需求
针对股票新闻数据集,以新闻标题中的词组为key,编写带URL属性的文档倒排索引程序,将结果输出到指定文件。
主要设计思路
可将需求具体拆解成如下步骤:
- 在WordCount.java中获取股票新闻标题分词+url
- 在InvertedIndexer.java中输出词组+url
文件流设计如下: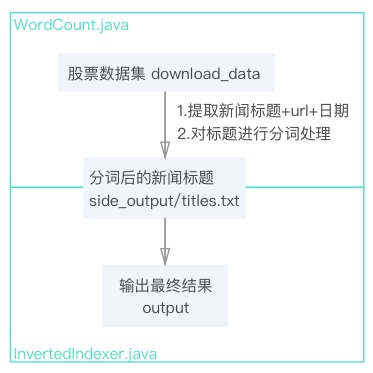
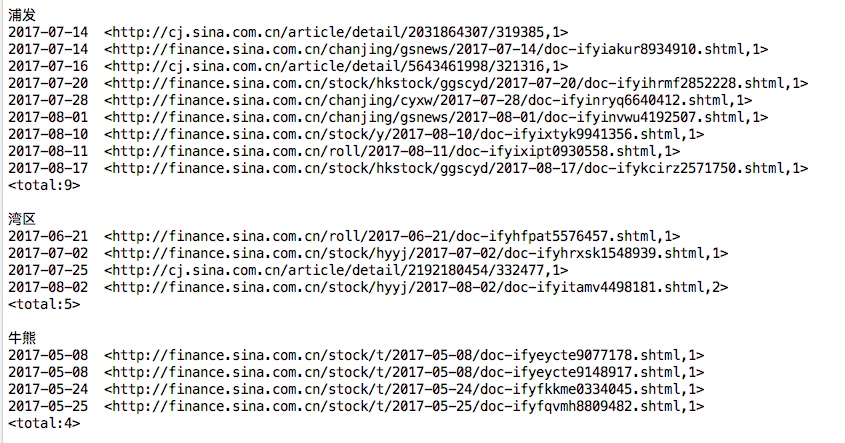
考虑到本数据集数据较大,一个词组会输出上万个url的情况,为了更加方便直观的查看词组对应的每个url,故将日期也同步以升序输出。
算法设计
需求本质是文档倒排索引,与传统的文档倒排索引不同的地方在于本程序并非以文档名称为索引,而是以新闻标题对应的url为索引,另外为了更加直观,本程序还对应输出了每个url对应的日期。
一个倒排作引由大量的posting列表组成,每一个posting列表和一个词组相关联,每个posting表示对应词组在一个文档的payload信息,包括URL、词频和新闻日期。
Mapper将 <词组#url#日期,词频> 作为输出的\<key,value>对,然后使用Combiner将Mapper的输出结果中value部分的词频进行统计;接着自定义 HashPartitioner,把组合的主键临时拆开,使得Partitioner单纯按照词组进行分区选择正确的Reduce节点,即将传入的key按照#进行分割出词组,使得 <词组#url#日期,词频>格式的key值只按照词组分发给Reducer,这样可保证同一个词组下的键值对一定被分到同一个Reduce节点。
Reducer从Partitioner得到键值对后,key值被进一步分割为词组、url和日期,由于Reduce自动按照key值升序排序,为了实现按照日期升序排序,故将url和日期的位置进行调换,即变成日期 url的形式,便可自动升序排序。
程序和各个类的设计说明
1.map方法
map( )函数使用自定义的FileNameRecordReader,将词组、url和日期以#作为分隔符,并将词组#url#日期整体作为key,频次作为value输出键值对。
相关代码:
1 | protected void map(Text key, Text value, Context context) |
2.Combiner类
Hadoop用过在Mapper类结束后、传入Reduce节点之前用一个Combiner类来解决相同主键键值对的合并处理。Combiner类主要作用是为了合并和减少Mapper的输出从而减少Reduce节点的负载。
本程序使用Combiner将Mapper的输出结果中value部分的词频进行统计。
相关代码片段:
1 | int sum = 0; |
3.Partitioner类
由于一个Reduce节点所处理的数据可能会来自多个Map节点,因此为了避免在Reduce计算过程中不同Reduce节点间存在数据相关性,需要一个Partitioner的过程。Partitioner用来控制Map输出的中间结果键值对的划分,分区总数与作业的Reduce任务的数量一致。
本程序自定义一个HashPartitioner类,先继承Partitioner类,并重载getPartition( )方法。 getPartition( )方法返回一个0到Reducer数目之间的整型值来确定将<key,value>送到哪一个Reducer中,它的参数除了key和value之外还有一个numReduceTasks表示总的划分的个数。
HashPartitioner把组合的主键临时拆开,使得Partitioner将传入的key按照#进行分割出词组,只按照词组进行分区选择正确的Reduce节点,这样可保证同一个词组下的键值对一定被分到同一个Reduce节点。
相关代码:
1 | public static class NewPartitioner extends HashPartitioner<Text, IntWritable> { |
4.Reducer类
Reduce( )方法主要实现以下功能:
- 将key按照
#进行分割 - 交换原key中url和日期的顺序
- 针对每个词组输出对应的多个url和日期
- 对词组出现的次数进行计数
- 筛选一定频次的词组并输出
程序运行和实验结果说明和分析
程序运行说明
本程序对需求做了进一步改进,能够具体索引一个频次段的词组的url,共设置4个参数,分别为 <文件输入路径> <输出结果路径> <频次下限> <频次上限>
此处<files input path>是指新闻标题分词后带有url和日期的文件,形式如下: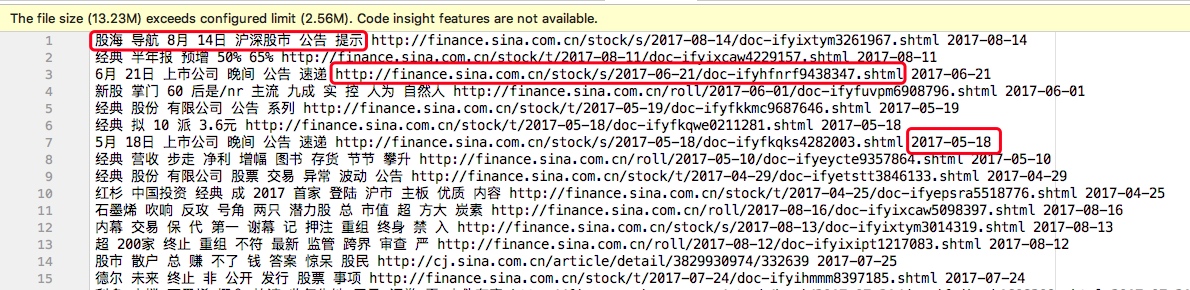
需要注意的一点是由于hdfs文件路径的限制,数据集的路径直接在程序中给出而非作为参数给出:
实验结果截图
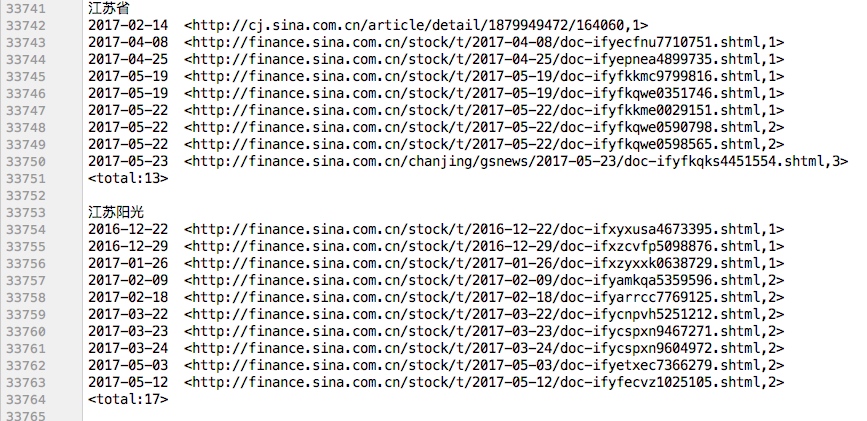
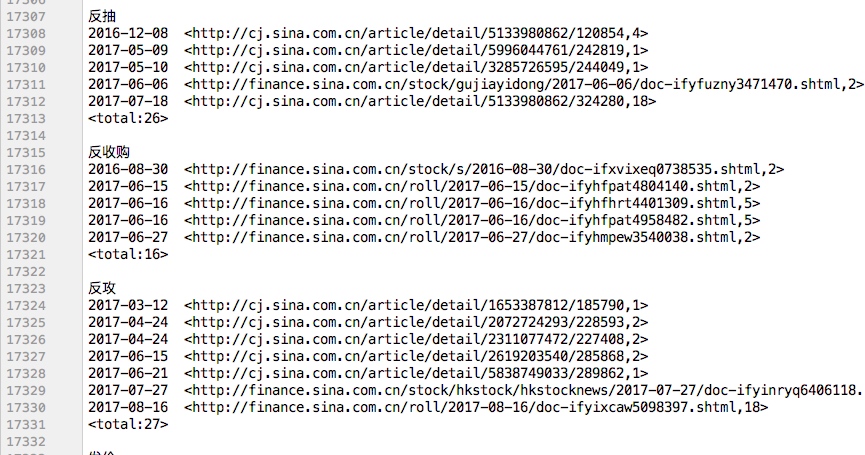
由于输出html太多不方便查看结果,取频次15~29次词组运行本程序
输入参数:
创新点
- 为了使数据更有意义,在新闻标题url输出的同时同步输出对应日期
- 为了方便查看,每个词组对应的url按照日期从旧到新的顺序输出
可改进之处
- 可把词组检索结果按照日期降序输出,即时间上由新到旧的顺序
- 当词组出现的次数太大时,可设置一种排序机制只输出排序前50个url