需求
针对股票新闻数据集中的新闻标题,编写WordCount程序,统计所有除Stop-word(如“的”,“得”,“在”等)出现次数k次以上的单词计数,最后的结果按照词频从高到低排序输出。
主要设计思路
可将需求具体拆解成如下几个步骤:
- 批量读取文件提取新闻标题
- 将新闻标题分词
- 对分词后的结果进行词频统计
- 根据词频降序输出
文件流设计如下: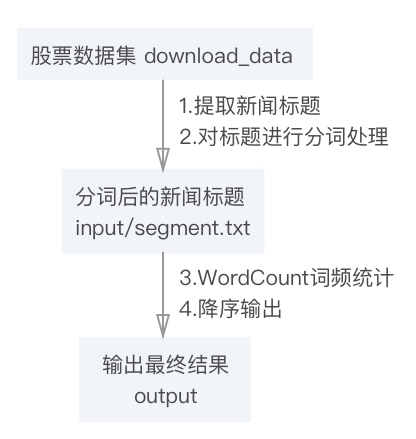
算法设计
需求对于传统WordCount的改进是分词和降序输出,其中核心部分是降序输出。
用一个并行计算任务无法同时完成单词词频统计和排序的,可以利用 Hadoop 的任务管道能力,用上一个任务(词频统计)的输出做为下一个任务(排序)的输入,顺序执行两个并行计算任务。
MapReduce 会把中间结果根据 key 排序并按 key 切成n份交给n个 Reduce 函数,Reduce 函数在处理中间结果之前也会有一个按 key 进行升序排序的过程,故 MapReduce 输出的最终结果实际上已经按 key 排好序。
传统的WordCount输出是将 <词组,频次> 作为 <key,value> 对,然后MapReduce默认根据 key 值升序输出,为了实现按词频降序排序,这里使用hadoop内置InverseMapper 类作为排序任务的 Mapper 类 sortjob.setMapperClass(InverseMapper.class) ,这个类的 map 函数将输入的 key 和 value 互换后作为中间结果输出,即将词频作为 key, 单词作为 value 输出, 然后得到按照词频升序排序的结果。
接下来需要解决将升序改为降序的问题。
此处可以利用hadoop内置比较类Class WritableComparator实现一个降序排序函数,官方API截图如下:

程序和各个类的设计说明
1.批量读取文件
本程序所用数据集:
某门户网站财经板块股票新闻数据集:download_data.zip
1.1 内容:收集沪市和深市若干支股票在某时间段内的若干条财经新闻标题
1.2 格式:文件名:股票代号+股票名.txt;文件内容:股票代码+时间+新闻标题+网页URL(以空格分隔)
首先用hadoop遍历文件夹的内置方法iteratorPath遍历给定数据集并对每个txt文件进行操作分词操作并输出两个文件:
- 用于作为下一步输入的
segment.txt(标题) - 用于需求2文档倒排的
titles.txt(标题+url+日期)
2.分词
Java分布式中文分词组件 - word分词
word分词是一个Java实现的分布式的中文分词组件,提供了多种基于词典的分词算法,并利用ngram模型来消除歧义。能准确识别英文、数字,以及日期、时间等数量词,能识别人名、地名、组织机构名等未登录词。能通过自定义配置文件来改变组件行为,能自定义用户词库、自动检测词库变化、支持大规模分布式环境,能灵活指定多种分词算法,能使用refine功能灵活控制分词结果,还能使用词频统计、词性标注、同义标注、反义标注、拼音标注等功能。提供了10种分词算法,还提供了10种文本相似度算法,同时还无缝和Lucene、Solr、ElasticSearch、Luke集成。注意:word1.3需要JDK1.8
下载API然后在project中引入jar包即可直接在程序中使用
为了避免多余的文件操作,本程序在提取新闻标题后写入txt文件前进行分词操作,可以输出分词结果。即先分词后输出。
相关代码如下:
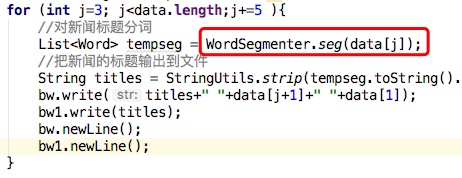
3.词频统计WordCount
mapper类
这个类实现 Mapper 接口中的 map 方法,输入参数中的 value 是文本文件中的一行,利用 StringTokenizer 将这个字符串拆成单词,然后将输出结果 <词组,1> 写入到 org.apache.hadoop.io.Text 中。
相关代码:
1 | public void map(Object key, Text value, Context context) |
reducer类
这个类实现 Reducer 接口中的 reduce 方法, 输入参数中的 key, values 是由 Map 任务输出的中间结果,values 是一个 Iterator, 遍历这个 Iterator, 就可以得到属于同一个 key 的所有 value。在本程序中key 是一个单词,value 是词频。只需要将所有的 value 相加,就可以得到这个单词的总的出现次数。
相关代码:
1 | public void reduce(Text key, Iterable<IntWritable> values, Context context) |
4.根据词频降序
用hadoop内置类IntWritable.Comparator实现一个函数IntWritableDecreasingComparator 对key进行比较并降序输出
相关代码:
1 | private static class IntWritableDecreasingComparator extends IntWritable.Comparator { |
程序运行和实验结果说明和分析
程序运行说明
wordcount.java 需求是将大于k次以上的词组以降序输出,本程序对需求做了进一步改进,能够具体输出一个频次段的词组,共设置4个参数,分别为 <文件输入路径> <输出结果路径> <频次下限> <频次上限>
此处<files input path>是指WordCount的输入路径,即分词的输出文件,此处只需提供一个空文件夹即可
实验结果截图
以输出频次在4500~6500的词组为例运行程序:
输入参数:
运行结果: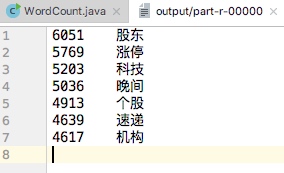
创新点
本次需求是将股票新闻标题中出现k次以上的单词按照词频降序输出,由于考虑到频次太低和频次太高的词组对股票数据分析无太大意义,故本人将程序进一步优化,使得能够输出a~b之间的一段词频而非只是k次以上的词组。
| 频次最高的部分词组 | 频次最低的部分词组 |
|---|---|
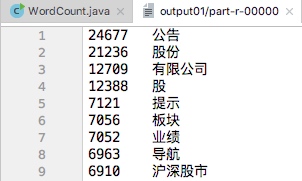 |
 |
存在的不足和可能的改进之处
- word分词器由于分词精确度较高、功能较为复杂的原因而运行时较慢,可用的解决方案是在对除了分词之外的其他功能无要求、分词难度不大的情况下可以考虑用其他可替代的轻量中文分词器
- 目前由于分词器的问题,仍会出现 一些奇奇怪怪的问题比如最终结果有一部分只输出标题不输出url等,解决方案是换个分词器……
- 可改进之处:把数据集的路径作为参数输入而非在程序中固定