Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
下面是mac OSx系统下Hadoop的安装、配置、运行示例和可视化查看。
安装homebrew
Homebrew 是一款开源的软件包管理系统,用以简化 macOS 上的软件安装过程,可以类比于 Windows 上软件管家的一键安装。Homebrew Cask 是 Homebrew 的扩展,借助它可以方便地在 macOS 上安装图形界面程序,即我们常用的各类应用。
在终端输入:
1 | ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" |
当出现如下时耐心等着:
1 | HEAD is now at a5b37e3b Merge pull request #3201 from MikeMcQuaid/git-coretap-tests |
直到:
1 | ==> Installation successful! |
安装成功!
安装homebrew cask
在终端输入:
1 | brew install caskroom/cask/brew-cask |
若出错,尝试以下来安装:
1 | brew tap caskroom/cask |
ps:没有安装Xcode的情况下会有错误提示,此时在终端中输入xcode-select--install,在弹出的窗口选择install以安装Commnd Line Tools, 路径为 /Library/Developer/CommandLineTools,不过建议安装Xcode
java安装/升级
用brew安装的Hadoop是最新版本,所需java最低版本为1.7.0,但mac自带的java版本为1.6.0
如果不确定自己的版本,可在终端输入 java -version查看
mac在java下有两种方式升级:
- 下载java更新包在本地安装
- 通过brew cask安装
既然下了brew cask为什么还要麻烦地去下载再手动安装呢??
老规矩,在终端输入:
1 | brew update && brew upgrade brew-cask && brew cleanup && brew cask cleanup$ brew cask install java |
啊哦在输入第一条命令后就出错了:
1 | Error: No available formula with the name "brew-cask" |
上Stack Overflow一查,解决方法:
1 | brew install brew-cask-completion |
接着输入上面的第二条命令应该就好了

安装好竟然还会出现一杯啤酒,超可爱
配置SSH
为了保证远程登录管理 Hadoop 及 Hadoop 节点用户共享的安全性,Hadoop 需要配置使用 SSH 协议
首先
系统偏好设置->共享->打开远程登录服务->右侧选择允许所有用户访问
在终端输入1
ssh localhost
若返回
1 | Last login: Sun Sep 24 13:12:04 2017 |
则配置成功,若不成功则继按以下顺序输入:(成功后也需要输入以下代码以避免每次登陆输入密码)
1 | ssh-keygen -t rsa |
然后应该就好了
原理是在当前用户目录下的.ssh文件夹(是一个隐藏文件)中生成一个id_rsa文件,然后授权你的公钥到本地可以避免每次登陆时都要询问你的密码
安装Hadoop
1 | brew install hadoop |
出现以下这样就安装完成了🍺
Hadoop环境配置
配置 hadoop-env.sh
打开文件 usr/local/Cellar/hadoop/2.8.1/libexec/etc/hadoop,注意将里面的2.8.1换成自己的hadoop版本号
打开hadoop-env.sh文件
将里面的
1 | export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true" |
修改为
1 | export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true -Djava.security.krb5.realm= -Djava.security.krb5.kdc=" |
配置 yarn-env.sh
打开刚才文件夹里的yarn-env.sh文件
加入
1 | YARN_OPTS="$YARN_OPTS -Djava.security.krb5.realm=OX.AC.UK -Djava.security.krb5.kdc=kdc0.ox.ac.uk:kdc1.ox.ac.uk" |
配置 core-site.xml
配置hdfs的地址和端口号,打开对应文件,在
1 | <property> |
配置 hdfs-core.xml
在
1 | <property> |
配置 mapred-site.xml
设置MapReduce中jobtracker的地址和端口号
同理添加
1 | <property> |
配置 yarn-site.xml
同理添加
1 | <property> |
配置hdfs-site.xml
hdfs备份方式默认值是3,在伪分布式系统中需要修改为1,同理添加
1 | <property> |
格式化HDFS
在终端输入
1 | rm -rf /tmp/hadoop-tanjiti #如果之前安装过需要清除 |
启动Hadoop
进入sbin目录(按国际惯例,把版本号换成自己的)
1 | cd /usr/local/Cellar/hadoop/2.8.1/sbin |
- 启动HDFS
1 | ./start-dfs.sh |
- 启动MapReduce
1 | ./start-yarn.sh |
- 检查启动情况
1 | jps |
出现以下结果
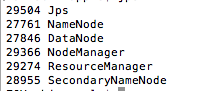
大功告成🍻
但每次执行命令都要进入sbin目录下,为了方便可以配置一下Hadoop环境变量
1 | sudo vim /etc/profile |
按i进入编辑模式,然后加入如下:
1 | export HADOOP_HOME=/usr/local/Cellar/hadoop/2.8.1 #你Hadoop的安装路径 |
esc后按:wq!保存退出 然后输入以下命令使文件生效
1 | source /etc/profile |
然后就可以愉快的在根目录下使用start-dfs.sh来启动Hadoop了
运行示例
进入目录/usr/local/Cellar/hadoop/2.8.1/libexec/share/hadoop/mapreduce/可运行示例计算π的值:
1 | hadoop jar hadoop-mapreduce-examples-2.8.1.jar pi 5 5 |
出现如下结果:

可视化查看
- 通过web接口查看
- Cluster Status http://localhost:8088
- HDFS status http://localhost:50070
- secondaryNamenode http://localhost:50090
在IntelliJ下运行hadoop程序
参考博客: http://blog.csdn.net/wk51920/article/details/51686337
一步步跟着做即可
相关博文:
mac下Hive+MySql环境配置
参考博客
- https://github.com/100steps/Blogs/issues/10
- http://codingxiaxw.cn/2016/12/06/59-mac-hadoop/
- http://www.jianshu.com/p/d19ce17234b7