Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
下面来一起看看Hive的安装和配置。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
下面来一起看看Hive的安装和配置。
股市新闻包含财务数据、经营公告、行业动向、国家政策等大量文本信息,包含了一定的情感倾向,影响股民对公司股票未来走势的预期,进一步造成公司的股价波动。如果能够挖掘出这些新闻中蕴含的情感信息,则可以对股票价格进行预测,对于指导投资有很大的作用。
本实验尝试使用文本挖掘技术和机器学习算法,挖掘出新闻中蕴含的情感信息,分别将每条新闻的情感判别为“positive”、“neutral”、“negative”这三种情感中的一种,可根据抓取的所有新闻的情感汇总分析来对股票价格做预测。
样本集:指标有negative、 neutral、positive词性的数据集
测试集:指待分类股票标题数据集
将需求主要要分解成如下几个步骤:
1 | String titles = StringUtils.strip(tempseg.toString().replaceAll("[,.%/(A-Za-z0-9)]",""),"[]"); |
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
来源:百度百科
TF(term frequency)即一个词在该文本中的词频
IDF(inverse document frequency)是指逆向文件频率
一个词的Tf-Idf值标识着它对于该文本的重要性,即一个词在该文本中出现的次数越多而在整个语料库中出现的次数越少就越能说明这个词能在很大程度上代表这个文本。故Tf-Idf相对于单纯的词频统计来说能够使得在所有文本中都出现的词如“股票”“公司”“新闻”等的权重下降,从而突出能够代表文本的特征词
因此可以用Tf-Idf值可以过滤常用词并保留重要词,总而可以进行特征选择
Tf-Idf的java实现为分别计算一个词的tf值和idf值,然后将两者相乘(并扩大10000倍)作为其Tf-Idf值,并和对应的词组映射在哈希表最后将结果按照tf-idf值降序输出
tf值计算:
1 | int wordLen = cutwords.size(); |
idf值计算:
1 | float value = (float)Math.log(docNum / Float.parseFloat(entry.getValue().toString())); |
tf-idf计算:
1 | while(iter.hasNext()){ |
文本向量化主要思路:
features.txt(包含1500个特征词)关键部分代码:
1 | while ((temp0 = br1.readLine()) != null) { |
KNN就是根据某种距离度量检测未知数据与已知数据的距离,统计其中距离最近的k个已知数据的类别,以多数投票的形式确定未知数据的类别。
源程序共定义了三个class文件,分别是:
public void read() :读取文件中的数据,存储为数组的形式(以嵌套链表的形式实现)List<List
main :读入样本集和测试集的数据,然后输出测试集的分类
在此程序中由于需要分为negative、neutral、positive三类,故k=3
此程序定义了一个大小为k的优先级队列来存储k个最近邻节点
优先级队列初始默认是距离越远越优先
根据算法中的实现,将与测试集最近的k个节点保存下来
用来存储最近邻的k个元组相关的信息
训练集:knntrain.txt
格式:【tfidf值1】【tfidf值2】···【tfidf值1500】【 分类标号】
示例:(以二维数据为例)
1 | 0.1887 0.3276 -1 |
测试集:knndata.txt
格式:【tfidf值1】【tfidf值2】···【tfidf值1500】
示例:(以二维数据为例)
1 | 0.9516 0.0326 |
股票数据集KNN算法输出结果部分截图:

NaiveBayesMain.java 主程序入口
NaiveBayesConf.java 用于处理配置文件
NaiveBayesTrain.java 用于训练过程的MapReduce 描述
NaiveBayesTrainData.java 在测试过程之前,读取训练后数据
NaiveBayesTest.java 用于测试(分类)过程的MapReduce 描述
配置文件NBayes.conf用于描述分类内容
格式:
举例说明:3个分类,类名为cl1,cl2,cl3;分类有3个属性(即词组),为p1,p2,p3
1 | 3 cl1 cl2 cl3 |
NBayes.train
用来存放训练集
每一行描述一个训练向量,每行第一个为类名,后面接M个值,空格分隔,代表此向量各属性值
举例:
1 | cl1 3 4 6 |
NBayes.test
用来存放测试集
每一行描述一个训练向量,每行第一个该变量ID,后面接M个值,空格分隔,代表此向量各属性值
举例:
1 | 1 6 9 3 |
并不令人满意
Weka是一款免费的,非商业化的,基于JAVA环境下开源的机器学习(machine learning)以及数据挖掘(data mining)软件。
来源:百度百科
weka具有GUI图形界面&java调用接口
arff.java负责根据样本集和数据集来生成weka所需的输入文件格式为.arff格式
arff需要属性和分类,本程序把上一步生成的1000维tfidf数组作为1000个词组属性,把positive、neutral、negative作为分类。
训练集:1500实例,1001属性(1000维+1分类)
来源:weka GUI界面
数据集:3267实例(3267个股票),1001属性
来源:weka GUI界面
weka.java调用weka接口,实现了朴素贝叶斯、决策树、随机森林三个机器学习算法的数据挖掘
1 | //此方法负责把分类后生成的arff结果文件中的 |
1 | //此方法负责训练分类器并对数据集进行分类并进行交叉验证评估 |
三种算法正确率评估截图(用样本集交叉验证评估):

三种算法分类后结果部分对比:
朴素贝叶斯:
决策树:
随机森林:
针对股票新闻数据集,以新闻标题中的词组为key,编写带URL属性的文档倒排索引程序,将结果输出到指定文件。
可将需求具体拆解成如下步骤:
文件流设计如下: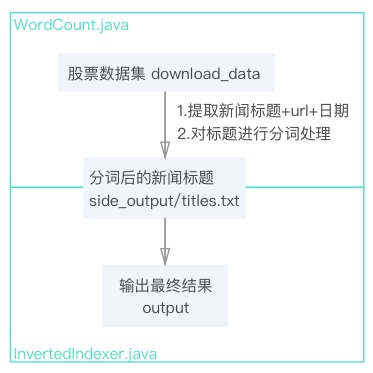
考虑到本数据集数据较大,一个词组会输出上万个url的情况,为了更加方便直观的查看词组对应的每个url,故将日期也同步以升序输出。
需求本质是文档倒排索引,与传统的文档倒排索引不同的地方在于本程序并非以文档名称为索引,而是以新闻标题对应的url为索引,另外为了更加直观,本程序还对应输出了每个url对应的日期。
一个倒排作引由大量的posting列表组成,每一个posting列表和一个词组相关联,每个posting表示对应词组在一个文档的payload信息,包括URL、词频和新闻日期。
Mapper将 <词组#url#日期,词频> 作为输出的\<key,value>对,然后使用Combiner将Mapper的输出结果中value部分的词频进行统计;接着自定义 HashPartitioner,把组合的主键临时拆开,使得Partitioner单纯按照词组进行分区选择正确的Reduce节点,即将传入的key按照#进行分割出词组,使得 <词组#url#日期,词频>格式的key值只按照词组分发给Reducer,这样可保证同一个词组下的键值对一定被分到同一个Reduce节点。
Reducer从Partitioner得到键值对后,key值被进一步分割为词组、url和日期,由于Reduce自动按照key值升序排序,为了实现按照日期升序排序,故将url和日期的位置进行调换,即变成日期 url的形式,便可自动升序排序。
map( )函数使用自定义的FileNameRecordReader,将词组、url和日期以#作为分隔符,并将词组#url#日期整体作为key,频次作为value输出键值对。
相关代码:
1 | protected void map(Text key, Text value, Context context) |
Hadoop用过在Mapper类结束后、传入Reduce节点之前用一个Combiner类来解决相同主键键值对的合并处理。Combiner类主要作用是为了合并和减少Mapper的输出从而减少Reduce节点的负载。
本程序使用Combiner将Mapper的输出结果中value部分的词频进行统计。
相关代码片段:
1 | int sum = 0; |
由于一个Reduce节点所处理的数据可能会来自多个Map节点,因此为了避免在Reduce计算过程中不同Reduce节点间存在数据相关性,需要一个Partitioner的过程。Partitioner用来控制Map输出的中间结果键值对的划分,分区总数与作业的Reduce任务的数量一致。
本程序自定义一个HashPartitioner类,先继承Partitioner类,并重载getPartition( )方法。 getPartition( )方法返回一个0到Reducer数目之间的整型值来确定将<key,value>送到哪一个Reducer中,它的参数除了key和value之外还有一个numReduceTasks表示总的划分的个数。
HashPartitioner把组合的主键临时拆开,使得Partitioner将传入的key按照#进行分割出词组,只按照词组进行分区选择正确的Reduce节点,这样可保证同一个词组下的键值对一定被分到同一个Reduce节点。
相关代码:
1 | public static class NewPartitioner extends HashPartitioner<Text, IntWritable> { |
Reduce( )方法主要实现以下功能:
#进行分割本程序对需求做了进一步改进,能够具体索引一个频次段的词组的url,共设置4个参数,分别为 <文件输入路径> <输出结果路径> <频次下限> <频次上限>
此处<files input path>是指新闻标题分词后带有url和日期的文件,形式如下: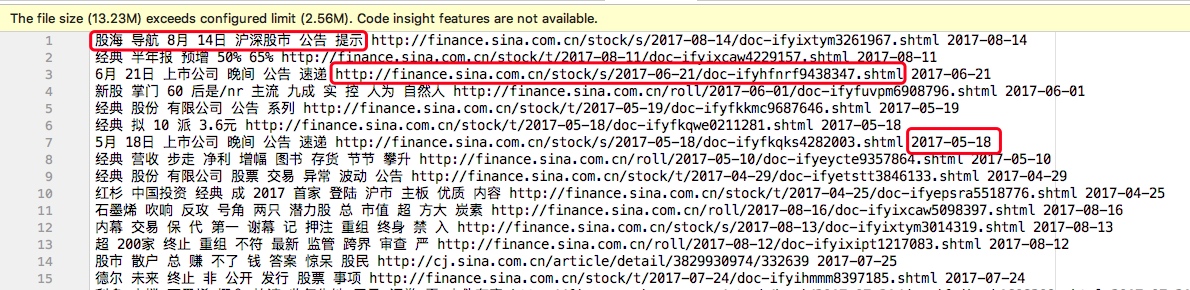
需要注意的一点是由于hdfs文件路径的限制,数据集的路径直接在程序中给出而非作为参数给出:
由于输出html太多不方便查看结果,取频次15~29次词组运行本程序
输入参数:
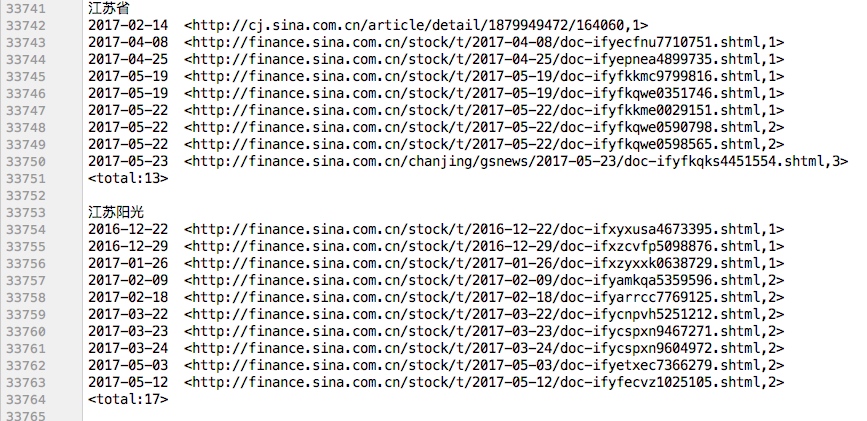
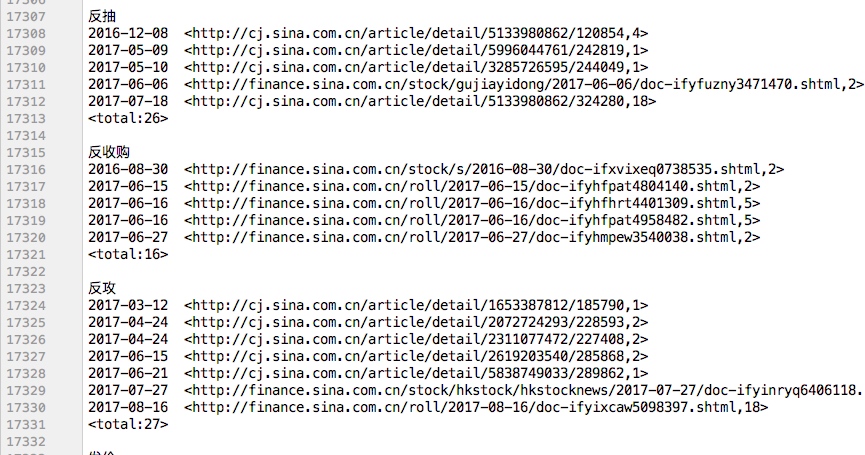
针对股票新闻数据集中的新闻标题,编写WordCount程序,统计所有除Stop-word(如“的”,“得”,“在”等)出现次数k次以上的单词计数,最后的结果按照词频从高到低排序输出。
可将需求具体拆解成如下几个步骤:
文件流设计如下: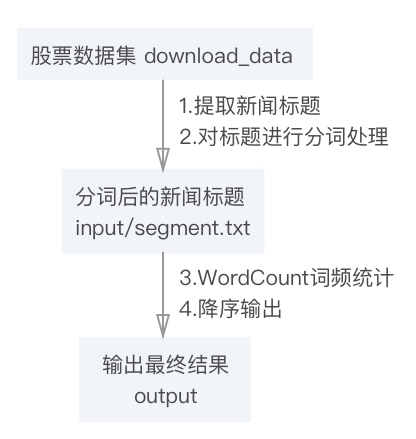
需求对于传统WordCount的改进是分词和降序输出,其中核心部分是降序输出。
用一个并行计算任务无法同时完成单词词频统计和排序的,可以利用 Hadoop 的任务管道能力,用上一个任务(词频统计)的输出做为下一个任务(排序)的输入,顺序执行两个并行计算任务。
MapReduce 会把中间结果根据 key 排序并按 key 切成n份交给n个 Reduce 函数,Reduce 函数在处理中间结果之前也会有一个按 key 进行升序排序的过程,故 MapReduce 输出的最终结果实际上已经按 key 排好序。
传统的WordCount输出是将 <词组,频次> 作为 <key,value> 对,然后MapReduce默认根据 key 值升序输出,为了实现按词频降序排序,这里使用hadoop内置InverseMapper 类作为排序任务的 Mapper 类 sortjob.setMapperClass(InverseMapper.class) ,这个类的 map 函数将输入的 key 和 value 互换后作为中间结果输出,即将词频作为 key, 单词作为 value 输出, 然后得到按照词频升序排序的结果。
接下来需要解决将升序改为降序的问题。
此处可以利用hadoop内置比较类Class WritableComparator实现一个降序排序函数,官方API截图如下:

本程序所用数据集:
某门户网站财经板块股票新闻数据集:download_data.zip
1.1 内容:收集沪市和深市若干支股票在某时间段内的若干条财经新闻标题
1.2 格式:文件名:股票代号+股票名.txt;文件内容:股票代码+时间+新闻标题+网页URL(以空格分隔)
首先用hadoop遍历文件夹的内置方法iteratorPath遍历给定数据集并对每个txt文件进行操作分词操作并输出两个文件:
segment.txt(标题)titles.txt(标题+url+日期)Java分布式中文分词组件 - word分词
word分词是一个Java实现的分布式的中文分词组件,提供了多种基于词典的分词算法,并利用ngram模型来消除歧义。能准确识别英文、数字,以及日期、时间等数量词,能识别人名、地名、组织机构名等未登录词。能通过自定义配置文件来改变组件行为,能自定义用户词库、自动检测词库变化、支持大规模分布式环境,能灵活指定多种分词算法,能使用refine功能灵活控制分词结果,还能使用词频统计、词性标注、同义标注、反义标注、拼音标注等功能。提供了10种分词算法,还提供了10种文本相似度算法,同时还无缝和Lucene、Solr、ElasticSearch、Luke集成。注意:word1.3需要JDK1.8
下载API然后在project中引入jar包即可直接在程序中使用
为了避免多余的文件操作,本程序在提取新闻标题后写入txt文件前进行分词操作,可以输出分词结果。即先分词后输出。
相关代码如下:
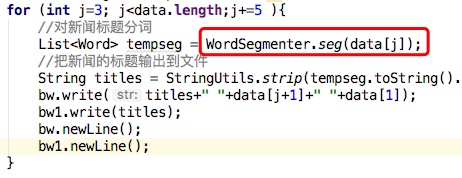
这个类实现 Mapper 接口中的 map 方法,输入参数中的 value 是文本文件中的一行,利用 StringTokenizer 将这个字符串拆成单词,然后将输出结果 <词组,1> 写入到 org.apache.hadoop.io.Text 中。
相关代码:
1 | public void map(Object key, Text value, Context context) |
这个类实现 Reducer 接口中的 reduce 方法, 输入参数中的 key, values 是由 Map 任务输出的中间结果,values 是一个 Iterator, 遍历这个 Iterator, 就可以得到属于同一个 key 的所有 value。在本程序中key 是一个单词,value 是词频。只需要将所有的 value 相加,就可以得到这个单词的总的出现次数。
相关代码:
1 | public void reduce(Text key, Iterable<IntWritable> values, Context context) |
用hadoop内置类IntWritable.Comparator实现一个函数IntWritableDecreasingComparator 对key进行比较并降序输出
相关代码:
1 | private static class IntWritableDecreasingComparator extends IntWritable.Comparator { |
wordcount.java 需求是将大于k次以上的词组以降序输出,本程序对需求做了进一步改进,能够具体输出一个频次段的词组,共设置4个参数,分别为 <文件输入路径> <输出结果路径> <频次下限> <频次上限>
此处<files input path>是指WordCount的输入路径,即分词的输出文件,此处只需提供一个空文件夹即可
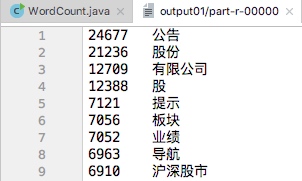
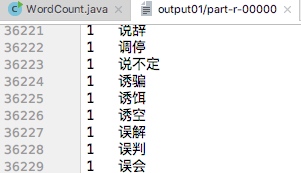
以输出频次在4500~6500的词组为例运行程序:
输入参数:
运行结果: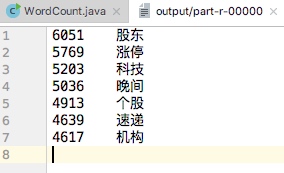
本次需求是将股票新闻标题中出现k次以上的单词按照词频降序输出,由于考虑到频次太低和频次太高的词组对股票数据分析无太大意义,故本人将程序进一步优化,使得能够输出a~b之间的一段词频而非只是k次以上的词组。
| 频次最高的部分词组 | 频次最低的部分词组 |
|---|---|
 |
 |